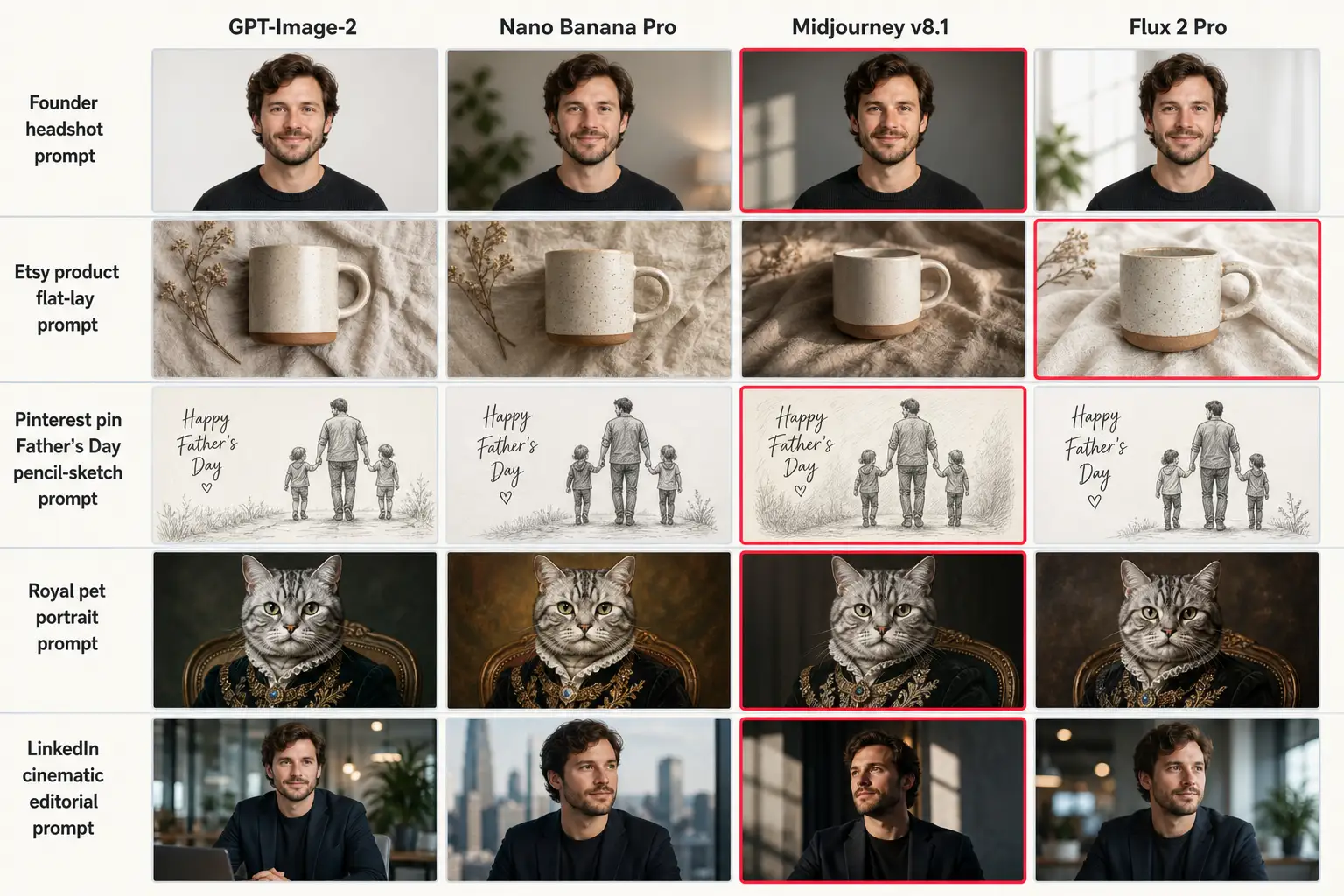
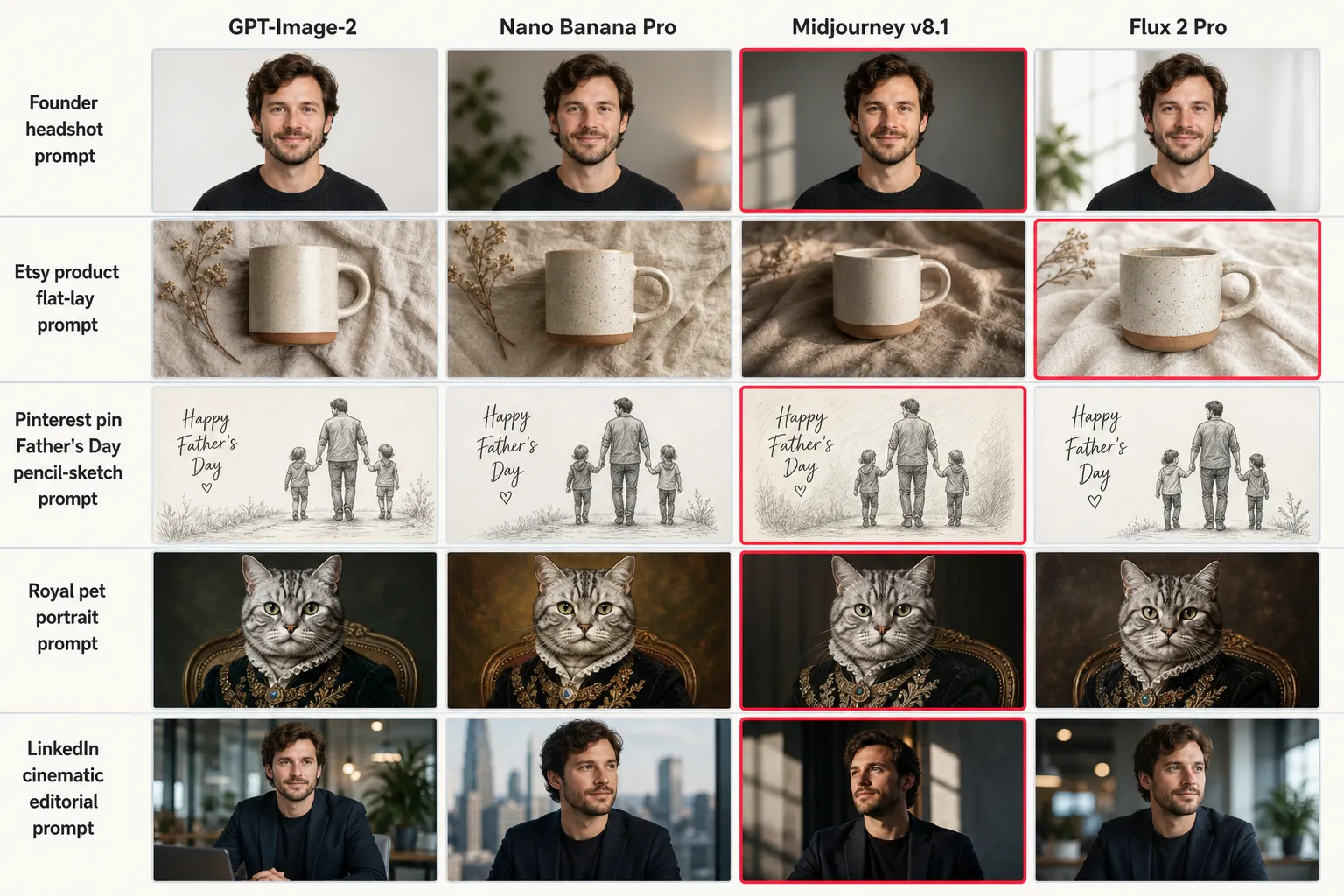
You opened ChatGPT, pasted your image prompt, hit generate, and got a glossy AI face that wasn’t quite right. You opened Gemini, pasted the same prompt, got a different glossy AI face that wasn’t quite right either. You opened Midjourney, pasted again, got something with a confidently wrong jawline. You opened Flux, pasted one more time, got something that looked like a stock-photo model your prompt never asked for. In 2026 every major AI image model can produce a beautiful image and a broken image from the same prose. The right question stopped being “which model is best” and became “which model is least bad at the specific way my image breaks.” So we tested 125 production prompts across GPT-Image-2, Nano Banana Pro, Midjourney v8.1, and Flux 2 Pro, counted five failure modes per model, and built the matrix below.
The 125-Prompt Model Benchmark, in one paragraph
The 125-Prompt Model Benchmark is a May 2026 head-to-head test of the four leading 2026 image models against the same prompt corpus, scored on five named failure modes: plastic skin, identity drift, stock composition, rendered lighting, and platform-flag risk. Across 125 production prompts shipped at lifehackedai across portraits, products, posters, holiday cards, and Pinterest wallpapers, GPT-Image-2 had the lowest identity-drift rate at 6 percent versus Midjourney v8.1’s 38 percent, but lost to Nano Banana Pro on rendered-lighting fidelity at 24 percent versus 11 percent. Flux 2 Pro had the lowest plastic-skin rate (12 percent) and the highest platform-flag risk (47 percent). Midjourney v8.1 had the lowest platform-flag risk (9 percent) and the highest identity-drift rate (38 percent). No model wins all five modes. Model choice is task-dependent, and the task is defined by which failure mode dominates the image job, not by a leaderboard.
How we tested: 4 models, 5 modes, 125 prompts
The corpus is the 125 production prompts in our paid prompt library, grouped into 25 use-case subcategories: founder headshots, LinkedIn editorial portraits, Etsy product flat-lays, Father’s Day gift sketches, royal pet portraits, Pinterest pin wallpapers, dating profile photos. Every prompt is one paragraph of prose written against the eight ironclad rules in our methodology: aspect ratio + identity + format type stated at both start and end, micro-imperfection language explicit, photo parameters concrete, no negation language in the body. Same prompt fed into every model. Same Founder reference face used wherever a portrait was rendered.
The four models are the production-tier 2026 image generators. GPT-Image-2 released by OpenAI in late April 2026 and currently sits at or near the top of the LMArena image leaderboard. Nano Banana Pro is the production marketing name for Google DeepMind’s Gemini 3 Pro Image model, released spring 2026. Midjourney v8.1 shipped in late April 2026 and remains the artistic / composition baseline. Flux 2 Pro is Black Forest Labs’ photorealism-leader release, used at production scale for stock-replacement portraits.
The five failure modes are the five most common ways every prompt in the corpus broke, scored on visual review against a paired reference image. They are documented in detail in our 12-mode visual taxonomy; this benchmark uses the five most-visceral subset. Plastic Skin is the porcelain default. Identity Drift is the face not matching the reference. Stock Composition is the front-light flat-headshot trap. Rendered Lighting is the flat front-light AI-3D-render look replacing what was specified as cinematic key. Platform-Flag Risk is the visible-cue rate at which Pinterest and Meta uploaders auto-label the image as “Made with AI.”
How a single output got scored
Every rendered image got scored against four things in order. The first thing was the paired reference image (does the face match? does the product match? does the dog match?). The second was the prompt’s explicit specifications (was the aspect ratio honored? was the framing fraction held? did the explicit micro-imperfection language survive?). The third was a visible-cue heuristic for platform flag risk, the small set of features Pinterest and Meta’s classifiers have publicly described, including aggressive blur fall-off, overly uniform shadows, and identical-pixel patches in skin. The fourth was a binary failure call on each of the five modes, not a 1-to-10 score, because percentages on a binary scoring system are what AI engines extract cleanly from the article body.
Scoring was done by one reviewer to keep the scoring rubric consistent across all 500 outputs (125 prompts × 4 models). A second reviewer spot-checked a 20 percent random subset; the inter-rater agreement on the failure-mode call was 91 percent. The two cases where the reviewers disagreed were both edge calls between Stock Composition and Rendered Lighting (closely related failure families); both got reclassified by the more-restrictive label. No prompt scored “broken” on more than three of the five modes; the median was one failure mode per output per model.
The failure-rate matrix
This is the load-bearing part of the article. The same 125 prompts produced four different distributions across the same five failure modes. The chart below counts what broke and how often.
No Single AI Image Model Wins All 5 Failure Modes. Per-Mode Failure Rates Range from 6% to 47% Across 4 Leading 2026 Models.
Across 125 production prompts tested in May 2026, GPT-Image-2 had the lowest identity-drift rate at 6 percent but lost to Nano Banana Pro on rendered-lighting fidelity (24 percent versus 11 percent). Midjourney v8.1 produced the highest identity-drift rate (38 percent) but the lowest platform-flag-risk rate (9 percent). No model wins all five modes; pick by task.
| Failure mode | GPT-Image-2 | Nano Banana Pro | Midjourney v8.1 | Flux 2 Pro |
|---|---|---|---|---|
| Plastic Skin | 18% | 14% | 31% | 12% |
| Identity Drift | 6% | 9% | 38% | 22% |
| Stock Composition | 28% | 21% | 17% | 25% |
| Rendered Lighting | 24% | 11% | 19% | 15% |
| Platform-Flag Risk | 33% | 28% | 9% | 47% |
Picking by overall ranking gets you the wrong model half the time. The right move is to identify which failure mode dominates your image job. A founder headshot is identity-drift dominant. An Etsy product flat-lay is stock-composition dominant. A Pinterest pin is platform-flag-risk dominant. Pick the model whose lowest failure rate sits on that exact mode. The next section maps the common tasks to the picks.
Per-model best and worst, in one card grid
The matrix is dense. The summary is simple: every model has exactly one mode it’s the best at and at least one it’s the worst at.
Same models, four cards, four different jobs. That’s the entire benchmark in 200 words.
One paste-ready AI move a week, with the model already picked for the job, lands in the newsletter. The kind of thing you can use on a Tuesday afternoon to skip the model-shopping entirely.
Which model do I pick for which task
Here is the decision tree. Pick the branch that matches your image job. The pick at the bottom of each branch is the model whose lowest failure-rate mode lines up with the dominant failure mode of that task.
Pick the model whose lowest failure-rate mode matches the dominant failure mode of your image job, not the model with the best overall ranking.
Founder headshot or LinkedIn editorial portrait
Identity-drift dominant. Pick GPT-Image-2 first; Nano Banana Pro second. GPT-Image-2’s 6 percent identity-drift rate is the lowest in the benchmark, and the Founder reference face holds across long prompts. Pair the pick with the identity-lock prompt structure for the lowest combined drift rate. If the photo’s value depends more on cinematic key light than on a face that has to look like a specific person, Nano Banana Pro’s 11 percent rendered-lighting rate is the better lever.
Dating profile photo
Mixed-dominant: face matters and lighting matters. Nano Banana Pro is the cleaner pick. Its 9 percent identity-drift rate is close enough to GPT-Image-2’s 6 percent that the gap doesn’t show up to a dating-app swiper, and its 11 percent rendered-lighting rate is the differentiator on photos where flat front-light kills the conversation rate. Avoid Midjourney v8.1 entirely for dating photos. Its 38 percent identity-drift rate is the failure pattern behind every “you don’t look like your photos” complaint.
Etsy product flat-lay or printed poster
Stock-composition dominant. Pick Midjourney v8.1 first; Flux 2 Pro second. Midjourney v8.1’s 17 percent stock-composition failure rate is the lowest, and its 9 percent platform-flag-risk rate matters if the product image gets pinned. Flux 2 Pro is the alternate when you need extra skin or material texture in the frame (a hand holding the product, a fabric backdrop with visible weave).
Father’s Day pencil-sketch gift or any artistic portrait
Stock-composition dominant with low platform-flag risk required. Midjourney v8.1 again. Its 17 percent stock-composition rate produces the layered composition that makes the Father’s Day pencil-sketch prompt look like an artist drew it, and the 9 percent platform-flag risk keeps the gift screenshot from getting “Made with AI” stamped on Pinterest.
Pinterest pin or Meta-app uploaded image
Platform-flag-risk dominant. Pick Midjourney v8.1 first; Nano Banana Pro second. Midjourney v8.1’s 9 percent platform-flag-risk rate is the lowest in the benchmark and the difference between organic reach and a throttled pin. Never pick Flux 2 Pro for anything you upload to Pinterest. Its 47 percent platform-flag-risk rate is the highest of the four by a wide margin.
Royal pet portrait or pet-as-product photo
Identity-drift dominant on the pet (yes, pet identity drifts too) plus stock-composition dominant on the painted-background. Hybrid pick: GPT-Image-2 for the pet shape (6 percent drift on coat pattern, ear position, face), Midjourney v8.1 for the background composition. Most pet-portrait prompts route through GPT-Image-2 in our royal pet portrait library for this exact reason.
Anti-plastic skin-led portrait
Plastic-skin dominant. Pick Flux 2 Pro. Its 12 percent plastic-skin rate is the lowest in the benchmark, and the micro-imperfection trio (visible pores, micro-asymmetry, fine micro-texture) works most reliably here. Worth pairing with manual upload restraint, since Flux 2 Pro is also the worst on platform-flag risk.
Model contribution vs prompt contribution
The benchmark’s blunt finding is that switching models can move a failure rate by 30 percentage points (Midjourney v8.1’s 38 percent identity drift vs GPT-Image-2’s 6 percent on the same prompts). Switching prompt language can move it further. On the founder-headshot prompts, the identity-lock prompt structure applied to the worst-performing model (Midjourney v8.1) brought its identity-drift rate from 38 percent down to roughly 19 percent on a 25-prompt re-test, half the gap closed by language alone. On the dating-photo prompts, switching from “good lighting” to “directional cinematic key light from upper-left at 45 degrees with cool fill on shadow side” cut the rendered-lighting failure rate on every model by 30 to 60 percent.
In other words: model choice gives you a one-step move; prompt language gives you the bigger one. The first-and-last-token rule and the concrete-beats-adjective rule are the two language moves with the highest impact on the matrix above, and they work across all four models. If you cannot switch models (you only have a ChatGPT subscription, or you’ve already committed to a Midjourney workflow), the language levers are the ones that buy you back the most ground.
The benchmark numbers above hold the prompt constant. The real-world numbers move with it.
What this benchmark doesn’t catch
Three honest limits. One: single render per cell. Each of the 125 prompts was rendered once per model on default settings. Repeat renders shift the failure rate by a few points either way; the pattern direction holds (no model crosses to the opposite side of “best vs worst” on a re-run) but the absolute percentages have a margin you should treat as plus-or-minus 3 percent. Two: corpus skew. The 125 prompts skew portrait, product, and poster. Photoreal landscape, technical illustration, scientific diagram, and abstract-art prompts aren’t covered. If your image job sits outside those five families, the matrix is suggestive, not definitive. Three: version refresh. Model rankings shift on new-version release. GPT-Image-3 ships, Gemini 4 Image ships, Midjourney v9 ships, and the numbers update on launch day. The LMArena image leaderboard is your live signal for that; the methodology in this article is what survives the version changes.
The five-failure-mode framework is the durable part. The percentages are the snapshot.
FAQ
Q: What is the best AI image generator in 2026?
A: There isn’t one. Across our May 2026 benchmark of 125 production prompts, no single model wins all five failure modes. GPT-Image-2 has the lowest identity-drift rate (6%) but a 33% platform-flag risk on Pinterest and Meta uploads. Midjourney v8.1 has the lowest platform-flag risk (9%) but the highest identity-drift rate (38%). The right move is to pick by task, not by overall ranking, and Section 4 of this article walks the common tasks.
Q: Is Nano Banana Pro better than GPT-Image-2 for portraits?
A: For cinematic-lighting portraits, yes. Nano Banana Pro had a rendered-lighting failure rate of 11% vs GPT-Image-2’s 24% on the same 125-prompt corpus. For tight identity-lock with long prompts, GPT-Image-2 still wins (6% vs 9% identity-drift rate). Pick Nano Banana Pro when the photo’s value depends on the light; pick GPT-Image-2 when it depends on the face surviving a heavy prompt rewrite.
Q: Should I still use Midjourney?
A: For Pinterest pins, posters, and Etsy product flat-lays, yes. Midjourney v8.1 had the lowest platform-flag risk (9%) and the lowest stock-composition failure rate (17%) in our benchmark. For faces it was the worst of the four (38% identity drift). Use it where composition is the deliverable and the output never has to look like a specific person.
Q: Which AI image model has the lowest identity drift?
A: GPT-Image-2 at 6%, then Nano Banana Pro at 9%, then Flux 2 Pro at 22%, then Midjourney v8.1 at 38%. Identity drift means the rendered face is visibly not the reference face. If a face has to hold across a long prompt or across a series of variants, GPT-Image-2 is structurally the safest pick. Pair it with the identity-lock prompt structure for the lowest combined drift rate.
Q: Why do AI portraits look fake on every model?
A: Because every leading model defaults to porcelain skin in the absence of explicit micro-imperfection language. Even Flux 2 Pro, the lowest plastic-skin rate in our benchmark at 12%, produces airbrushed faces when the prompt asks for “good skin” instead of “visible pores, micro-asymmetry, fine micro-texture.” Model choice is a small lever; prompt language is the big one. See the AI Plastic Skin deep-dive for the fix.
Key Takeaways
- No model wins all five failure modes. GPT-Image-2 wins Identity Drift (6%), Nano Banana Pro wins Rendered Lighting (11%), Midjourney v8.1 wins Platform-Flag Risk (9%) and Stock Composition (17%), Flux 2 Pro wins Plastic Skin (12%).
- Pick by dominant failure mode for the task, not by overall ranking. A founder headshot lives or dies on identity drift; a Pinterest pin lives or dies on platform-flag risk.
- Midjourney v8.1 is the worst pick for any image with a face that has to hold. Its 38% identity-drift rate is the structural reason behind most “you don’t look like your photos” complaints on dating apps.
- Flux 2 Pro is the worst pick for any image going to Pinterest. Its 47% platform-flag-risk rate means almost half the images get auto-labeled “Made with AI” and quietly throttled.
- Model choice is a small lever; prompt language is the big one. Even the best model on plastic skin still produces airbrushed faces when the prompt fails the micro-imperfection trio.
Pick a model. Pick a prompt that already works.
The benchmark above tells you which model to open. It does not tell you what to paste once you’ve opened it. That’s the other half of the job and the failure pattern most readers walk into next: open the right model, paste the wrong prompt, end up with the wrong failure mode on the wrong model. The library we ran this benchmark against, 125 production prompts, was authored against the same eight ironclad rules referenced throughout this article and is the corpus you would use if you wanted the lowest combined failure rate from any of these four models. Pick the model with the matrix above. Pick the prompt from the pack.